ในการสร้างและนำคอมพิวเตอร์มาใช้งาน เราต้องการที่จะรู้ว่าแต่ละเครื่องที่ถูกสร้างขึ้นมีประสิทธิภาพมากน้อยต่างกันแค่ไหนบ้าง ซึ่งโดยทั่วไปเราใช้ benchmark หลายแบบในการวัดประสิทธิภาพของเครื่องในด้านต่างๆ เช่นความสามารถในการคำนวณ ความเร็วของ network เป็นต้น แต่การวัดอีกอันหนึ่งซึ่งมีความสำคัญมากไม่แพ้กันคือการวัด memory bandwidth ของเครื่อง
โดยทั่วไปสิ่งที่เราจะวัดเป็นอันดับแรกคือประสิทธิภาพของการคำนวณ เช่นสามารถประมวลผล floating-point operator ได้เท่าไหร่ในหนึ่งหน่วยเวลา แต่ค่านี้อาจจะยังไม่สามารถบอกได้ทั้งหมดว่าถ้ามี application มาทำงานจริงแล้วจะเร็วแค่ไหน ความเร็วของ cpu เพิ่มขึ้นเร็วมากตาม Moore's law ที่เราคุ้นเคย แต่ว่าความเร็วของ memory เพิ่มขึ้นช้ากว่ามากๆ application จึงอาจถูกจำกัดความเร็วจาก memory แทนได้ ลองนึกถึงเวลาที่ cpu ทำงานได้เร็วมาก แต่โหลดข้อมูลจาก memory ขึ้นมาไม่ทัน สุดท้ายแล้ว cpu ก็จะว่างและใช้งานได้ไม่เต็มประสิทธิภาพ ดังนั้นการรู้ความสามารถของการโหลดข้อมูลจาก memory จึงมีความจำเป็นด้วยสาเหตุนี้
STREAM เป็น benchmark สำหรับวัด bandwidth ในการโหลดข้อมูลขึ้นมาทำงาน สามารถดาวน์โหลดได้จากเว็บไซต์ทางการเลยคือ https://www.cs.virginia.edu/stream/ ซึ่ง benchmark ที่ดาวน์โหลดมาจะใช้ OpenMP อยู่แล้วเราจึงใช้งานกับ cpu แบบหลาย core ได้เลย วิธีการใช้งานก็ง่ายมาก ข้างในตัวที่ดาวน์โหลดมาจะมี 2 เวอร์ชัน คือเวอร์ชันที่เป็น C และ Fortran โดยจะมาในชื่อ stream.c และ stream.f ตามลำดับ ใช้คำสั่ง make จะได้ไฟล์ stream_c.exe และ stream_f.exe มา ใช้ตัวใดตัวหนึ่งรันก็พอครับ ซึ่งในบทความนี้ผมจะใช้แต่ตัวภาษา C นะครับ จะไม่แตะตัว Fortran เลย
------------------------------------------------------------- STREAM version $Revision: 5.10 $ ------------------------------------------------------------- This system uses 8 bytes per array element. ------------------------------------------------------------- Array size = 10000000 (elements), Offset = 0 (elements) Memory per array = 76.3 MiB (= 0.1 GiB). Total memory required = 228.9 MiB (= 0.2 GiB). Each kernel will be executed 10 times. The *best* time for each kernel (excluding the first iteration) will be used to compute the reported bandwidth. ------------------------------------------------------------- Your clock granularity/precision appears to be 1 microseconds. Each test below will take on the order of 12965 microseconds. (= 12965 clock ticks) Increase the size of the arrays if this shows that you are not getting at least 20 clock ticks per test. ------------------------------------------------------------- WARNING -- The above is only a rough guideline. For best results, please be sure you know the precision of your system timer. ------------------------------------------------------------- Function Best Rate MB/s Avg time Min time Max time Copy: 11362.8 0.014319 0.014081 0.014382 Scale: 11972.4 0.014016 0.013364 0.014190 Add: 13314.9 0.019570 0.018025 0.019836 Triad: 13830.4 0.019408 0.017353 0.019686 ------------------------------------------------------------- Solution Validates: avg error less than 1.000000e-13 on all three arrays -------------------------------------------------------------
ผมใช้ตัว stream_c.exe รันเลยทันที ผลลัพธ์จะได้ออกมาแบบนี้ บรรทัดแรก จะบอกว่าทั้งหมดนี้เป็นผลลัพธ์ของ STREAM เวอร์ชัน 5.10 ตรง Array size คือบอกจำนวน element ของ array ที่ใช้ ที่ผมรันจะเป็น 10,000,000 และคิดเป็นขนาด 76.3 MB ในส่วนด้านล่างที่ดูเป็นตาราง ตัวเลขที่สำคัญคือตรง Best Rate MB/s ส่วนนี้จะบอก bandwidth ที่ได้จากการรัน ซึ่งจะมีทั้งหมด 4 ค่า มาจาก kernel ทั้ง 4 ตัว STREAM นั่นเอง ได้แก่ Copy, Scale, Add และ Triad โค้ดของ STREAM นั่นง่ายมากครับ kernel ทั้ง 4 ตัวที่กล่าวมาทำงานแบบนี้
| Name | Kernel |
| Copy | a[i] = b[i] |
| Scale | a[i] = q * b[i] |
| Add | a[i] = b[i] + c[i] |
| Triad | a[i] = b[i] + q * c[i] |
ซึ่ง Copy จะทำแค่ copy ข้อมูลจาก array b ไป a ปกติแล้วตัวนี้จะให้ค่าดีสุดครับ เพราะมันทำอะไรน้อยสุด
หลังจากนี้เราจะมาค่อยๆ ลองรีดประสิทธิภาพที่แท้จริงของเครื่องกันนะครับว่าเป็นเท่าไหร่กันแน่ ก่อนอื่นที่ต้องรู้ก่อนก็คือกฎการรัน STREAM คือ
ขนาดของ array แต่ละตัวต้องใหญ่กว่าอย่างน้อย 4 เท่าของขนาดของ Cache ที่ใหญ่ที่สุดรวมกัน
Cache ที่ใหญ่ที่สุดก็คือ cache level ล่างสุดของ cpu เรานั่นเอง เช่นในที่นี้ผมใช้ Intel® Xeon® Processor E5-2620 v3 ซึ่ง cache ใหญ่สุดของมันคือ 15MB (อ้างอิงจากที่นี่) ดังนั้นขนาดอาร์เรย์แต่ละตัวของผมควรจะเกิน 60MB ซึ่งตอนนี้มันเป็น 76.3MB ก็ถือว่าผ่าน กรณีเครื่องผมมี cpu เดียวแบบนี้ถือว่าโอเคแล้ว แต่ถ้าเครื่องมีหลาย cpu จะต้องเอาขนาด cache สูงสุดของทุกตัวมารวมกันก่อนนะครับ แต่ถ้ามีรุ่นเดียวกันนี้ 4 ตัว แปลว่า cache เป็น 60MB ดังนั้น array แต่ละตัวของผมควรจะใหญ่กว่า 240MB ครับ
ถ้า array ของเราเล็กเกินไป จะกำหนดขนาดใหม่ก็ไม่ยากครับ ในตอน compile ให้ใส่ option เข้าไปว่า -DSTREAM_ARRAY_SIZE=40000000 แบบนี้ก็จะได้ array จำนวน 40000000 elements แต่เวลาคิดต้องคิดเป็น bytes ครับ ก็เอาขนาดของ floating-point ที่ใช้คูณเข้าไป
cpu ของ Intel สามารถดู memory bandwidth สูงสุดตามทฤษฎี ได้จากเว็บของ Intel เอง เช่นของ cpu ที่ผมใช้ก็ดูจากเว็บนี้ได้เลย ซึ่งในนั้นจะบอกว่ารุ่นที่ผมใช้อยู่มี bandwidth สูงสุดคือ 59GB/s แต่ถ้าลองดูจาก benchmark ที่รันแล้ว kernel ที่ดีที่สุดยังได้แค่ 13.83GB/s เอง ที่เป็นแบบนี้เพราะ cpu ยังคำนวณได้ไม่เร็วพอ cpu มีถึง 6 cores แต่ว่าเราใช้แค่ cores เดียว ซึ่งเราจะใช้ OpenMP (ที่ซึ่งเขียนมาใน benchmark ให้เราอยู่แล้ว) ทำให้มันเร็วขึ้น ก่อนอื่นก็เพิ่ม flags -fopenmp ลงไปใน Makefile ลอง make ใหม่ และรันอีกครั้ง แต่ก่อนรันลองกำหนดจำนวน threads ให้เท่ากับจำนวน cores ซึ่งก็คือ 6 ก่อน ด้วยคำสั่ง export OMP_NUM_THREADS=6 แล้วก็รันเหมือนเดิม จะได้ผลลัพธ์ออกมาแบบนี้
------------------------------------------------------------- Number of Threads requested = 6 Number of Threads counted = 6 ------------------------------------------------------------- ... ------------------------------------------------------------- Function Best Rate MB/s Avg time Min time Max time Copy: 28808.3 0.005596 0.005554 0.005755 Scale: 27846.0 0.005781 0.005746 0.005881 Add: 30927.6 0.007819 0.007760 0.008004 Triad: 31152.6 0.007765 0.007704 0.007953 -------------------------------------------------------------
ในผลลัพธ์ใหม่ที่ได้ จะมีข้อความเพิ่มขึ้นมาบอกว่า เรารันด้วย threads เท่ากับ 6 และจะเห็นว่าทุก kernel มี bandwidth เพิ่มขึ้นจากเดิม แต่ยังห่างจาก 59GB/s อยู่พอสมควร โดย default แล้ว optimization flags ที่กำหนดมาใน Makefile จะเป็น -O2 ผมจะลองเปลี่ยนเป็น -O3 แล้วรันใหม่ดู
------------------------------------------------------------- Function Best Rate MB/s Avg time Min time Max time Copy: 40701.6 0.003970 0.003931 0.004059 Scale: 28622.7 0.005628 0.005590 0.005751 Add: 30584.7 0.007910 0.007847 0.008076 Triad: 31027.7 0.007783 0.007735 0.007928 -------------------------------------------------------------
ผลลัพธ์ที่ได้ก็จะเร็วขึ้นไปอีก อาจจะลองเล่นด้วยการปรับหา compiler flags ต่างๆ ที่เกี่ยวข้องดูครับ ว่าทำยังไงให้เร็วขึ้นได้อีกบ้าง แต่ผมจะลองเปลี่ยน compiler จาก gcc ไป icc ของ Intel ดูแล้วลองใช้ flags ง่ายๆ ต่อไปนี้ (ใน Makefile ของ STREAM มีตัวอย่างให้ครับ)
- -O3 เปิด optimization level 3
- -qopenmp ใช้ OpenMP
- -xcore-avx2 ใช้ชุดคำสั่ง AVX2
------------------------------------------------------------- Function Best Rate MB/s Avg time Min time Max time Copy: 42801.8 0.003780 0.003738 0.003872 Scale: 43276.5 0.003735 0.003697 0.003791 Add: 43368.8 0.005599 0.005534 0.005811 Triad: 43415.6 0.005589 0.005528 0.005784 -------------------------------------------------------------
จะเห็นว่าเร็วขึ้นมากทีเดียว ผมลองรันแบบกำหนดจำนวน threads ต่างๆดู เนื่องจาก cpu มี 6 cores และมี hyper-threadingด้วย ผมเลยลองตั้งแต่ 1 - 12 threads ซึ่งได้ประสิทธิภาพมาตามนี้
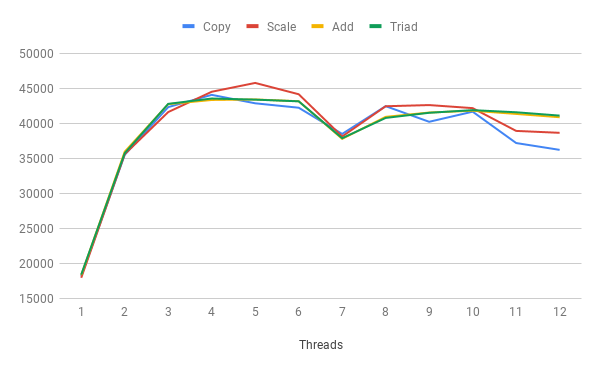
bandwidth จะขึ้นมา peak ที่ 5-6 threads และหลังจากนั้นก็จะเริ่มคงที่แล้ว ซึ่งแสดงว่ากำหนดจำนวน threads ให้เท่ากับ cores จริงๆ ไปเลยดีกว่า hyper-threading ไม่ช่วยอะไร
กรณีที่เครื่องที่เราต้องการวัดเป็นเครื่อง cluster ที่มีหลายเครื่องต่อกัน STREAM ก็มีเวอร์ชัน MPI ด้วยครับ หาได้จากเว็บหลักเลย แต่ต้องคุ้ยๆหน่อย คนทำบอกว่าไม่ชอบ MPI และไม่อยากเอาขึ้นเป็นตัว standard สำหรับการเทส STREAM บน cluster จำเป็นจะต้อง tune ตัว network ด้วยนะครับ เพื่อให้ bandwidth รวมไม่ตกลงเยอะ
Reference
- https://www.cs.virginia.edu/stream/
- McCalpin, John D., 1995: "Memory Bandwidth and Machine Balance in Current High Performance Computers", IEEE Computer Society Technical Committee on Computer Architecture (TCCA) Newsletter, December 1995.
Taxonomy upgrade extras:
- remixman's blog
- Log in to post comments